Musings On Neo4j
I’ve just finished watching a GeekOut video entitled Using ASCII art to analyse source code which introduced Neo4j’s Cypher syntax to me with some specific examples of its implementation.
This post is a musing on how to apply Neo4J in the payments world, and the kinds of analysis that would become possible using such a tool. I’ve never used Neo4J, and this is my first experiement in using it. Don’t assume I know what I’m talking about.
The Scenario
There are two main players in the scenario I’m considering, where the payment service provider is simply the mechanism to deliver these functions. The PSP itself may have some needs, but they’re not being considered here.
As a customer, I want to transfer money between myself and merchants so that merchants will provide me the services I require
As a merchant, I want to tools that provide information about my customers and transactions, So that I can make buisness decisions with the best information possible
The Graph
So given the scenario above, and some simple assumptions, I would have a few nodes;
- Customer
- PaymentMethod
- PaymentEvent
- Merchant
- MerchantBankDetails
I’m not too fussed right now about solving the specific needs of the Users defined above, but I am interested in understanding Neo4J a little more, with some more specific experiments.
Lets Experiment
So without further ado, lets get cracking.
Install
Rather than setting up a local machine, I’m going to use Heroku with a Neo4J addon to make my life simpler.
From the Documentation you just need to;
- Create an application: heroku apps:create your-app-name
- Add the Database Add-on: heroku addons:add graphenedb
- Open the Add-On Administration page: heroku addons:open graphenedb
If that works, you’ll find yourself at the GrapheneDB administration screen on a new heroku application. Magic.
Database
First steps, lets see how to create a new data record:
CREATE (c:customer { name:'Toby' })-[:PAYEE]->(p:payment { id:1234 }),
(m:merchant { name:'Bobs Cars' })-[:PAYMENT_FOR]->(p),
(pm:paymentMethod { type:'VISA', cardHash:'1234abcd'})-[:PAYMENT_METHOD]->(p),
(bd:bankDetails { bank:'BankOfToby', account_number:98765, accepts:['VISA'] })-[:BANK_DETAIL]->(m)
If you get that little record loaded into the administration console, you should be able to do a trivial query and get back a graph that looks something like this (I’ve renamed elements etc here)
MATCH n RETURN n LIMIT 25
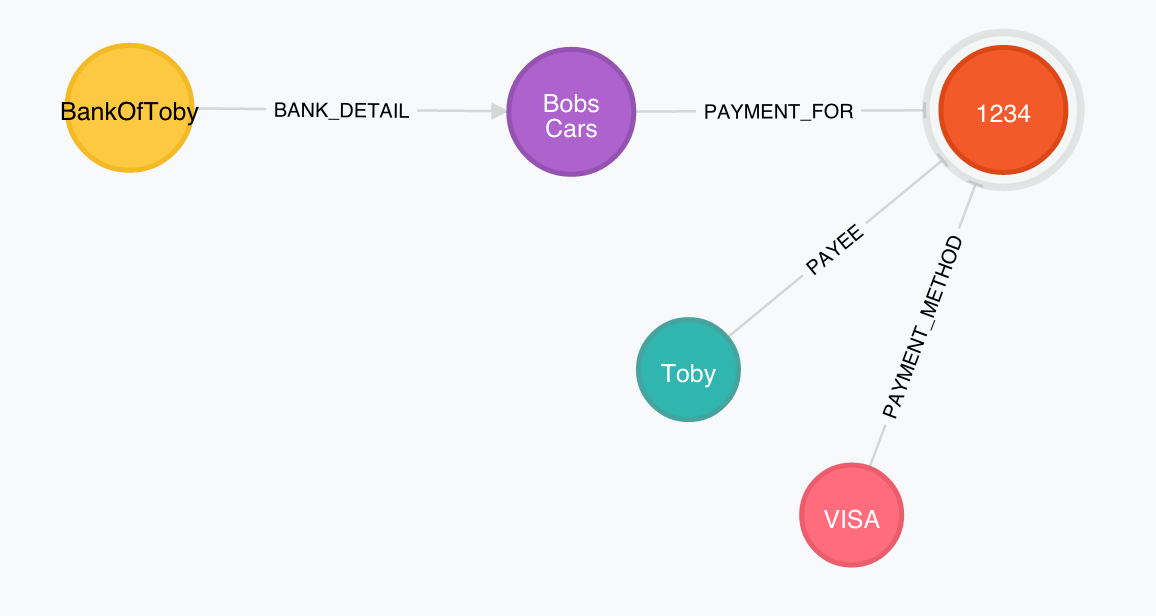
Add a link
So we probably want to associate customers with merchants directly, rather than inference through transactions, so we can update the database by performing a MATCH operations where we locate customers who’ve paid for a transaction, and the merchants who’ve had payments made to them, and then joining them update with a ‘customer_of’ relationship.
MATCH (c)-[:PAYEE]->(t)<-[:PAYMENT_FOR]-(m)
CREATE (c)-[:CUSTOMER_OF]->(m)
Bigger data
Having only a single record isn’t very interesting, so lets up the ante a little with some generated data.
I have created a set of demo data using generatedata.com which contains a bunch of ‘payments’ which you can use. To import into Neo4j you can use the following query:
LOAD CSV WITH HEADERS FROM "https://gist.github.com/warmfusion/90e91fe4e7a142bb2dbb/raw/c3925dff448aa77bb6ac87076e0d9efe5e1ce8c5/demo-dataset" AS csvLine
MERGE (c:customer { name: csvLine.name})
MERGE (pm:paymentMethod {cardNumber: csvLine.cardNumber })
MERGE (m:merchant {name: csvLine.merchant_name})
CREATE (p:payment {status: csvLine.status, amount: toFloat(csvLine.amount) })
CREATE (c)-[:PAYEE]->(p),
(p)-[:PAYMENT_FOR]->(m),
(pm)-[:PAYMENT_METHOD]->(p)
The use of MERGE above means that if Neo4j has already loaded a record that matches the defintion, it updates it, otherwise it’s created. This is particularlly useful for merchant records as we’re using 4 companies over and over and it wouldn’t make sense to create new unique nodes for each.
Note that Payment is a CREATE operation - This is because payments are never used more than once, and realistically the CSV should have some unique ID, but we’ll just create new records instead.
Declined Transactions for Tobys bikes
I’d like to know the transactions which have been declined for Tobys Bikes for a report. This can be done quite simply by creating a Match where we look for merchant by name, and follow any relationship to a payment which has been declined.
MATCH (m:merchant { name:'Tobys Bikes'})--(c:payment { status:'Declined'})
RETURN m,c
Find relationships between customers
Similar to the 6-degrees of Kevin Bacon, its actually very easy to find a relationship between two customers.
The sample dataset includes a few unusual associations, where the same credit card number is used by different customers, or more usually a customer makes payments to a few different merchants.
Because of this, the following query shows there is a relationship between Wynter Crosby and Gary Perry:
MATCH (wynter:customer { name:"Wynter Crosby" }),(gary:customer { name:"Gary Perry" }),
p = shortestPath((wynter)-[*..15]-(gary))
RETURN p
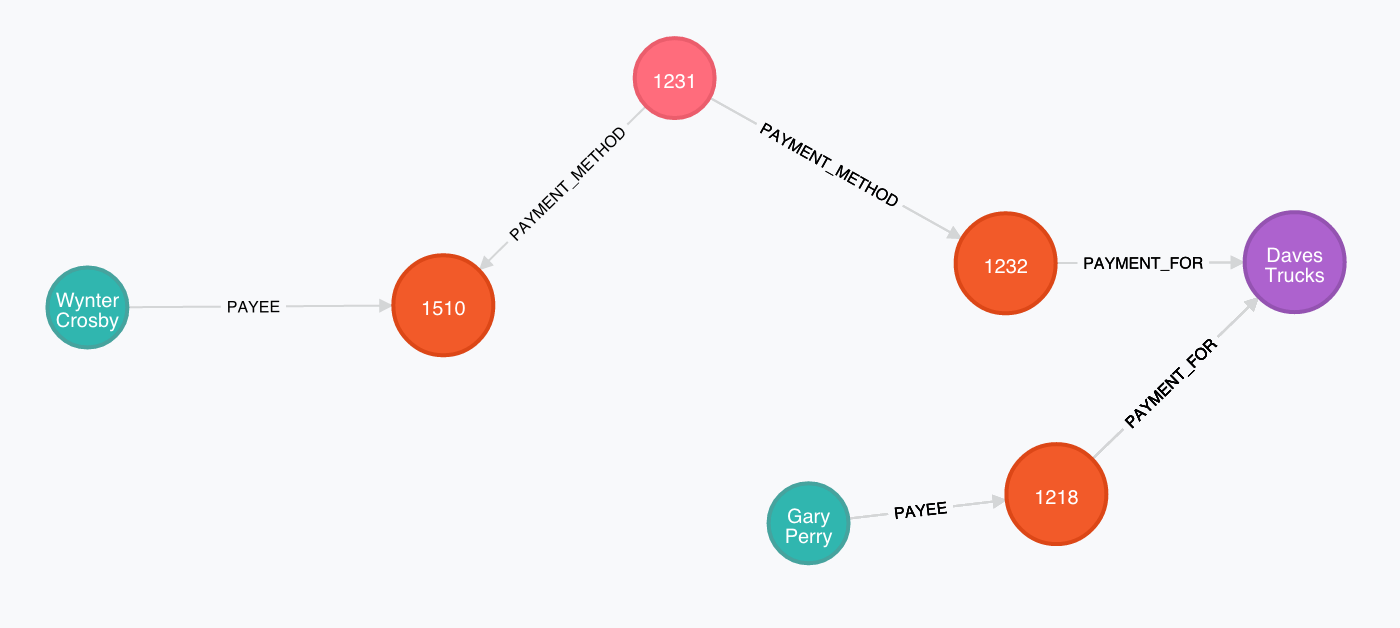
But what does this really show? Well, in this case it’s telling us that;
- Wynter made a payment using a credit card which was used again to pay Daves Trucks.
- Gary meanwhile simply made a payment to Daves Trucks as well…
So basically: Someone used Wynters credit card to buy something from the same place Gary did too…
Tip: Madeline Moss is the ‘missing link’ between these customers - She’s used Wynters card :-)
Finding Declines
Wondering how many transactions were declined for each merchant, I found the aggregate functions. This query returns a list of merchants and a sum of the unique payments which were Declined:
MATCH (m:merchant)--(p:payment {status:'Declined'})
RETURN DISTINCT m, count(DISTINCT p), sum(p.amount)
Conclusion
I think Neo4J is remarkably powerful, but I found myself slipping up on the definition of nodes and their relationships; How does a Payment relate to a merchant or a customer, is a customer related to a merchant directly, or just through their payments etc. Having too many relationships would likely impact on performance and scale.
I may experiment futher with considerably larger datasets, but will need to run locally to avoid the 1k node limit on heroku. It seems that mapping between a RDMS with foreign keys would be trivial to implement into a graph database as the join tables or key lookups are just replaced with directional relationships as required. Simple.
Tricks Learnt
Whilst writing this blog post, I found a few things tripped me up as I went. Nothing breaking with Neo4J, but just my approach itself.
Truncate Data
When you’ve got messed up data, you can start fresh by deleting all the records with this;
MATCH (n)
OPTIONAL MATCH (n)-[r]-()
DELETE n,r
Heroku Limit 1k Nodes
If you load too many elements, eg the csv a few times, you may find you go over the 1k node limit on the free graphene installation
You’ll need to totally remove and readd the addon as once it goes read-only you can’t even delete nodes… :-(
Directionality
I noticed that I’d gotten the Bank and Merchant relationship wrong earlier.. We actually want to point merchant to a bank detail. So to swap this relationship around, you find all the current nodes with the existing relationship, make a new one that points the other way, and remove the original relationships:
MATCH (bank)-[r:BANK_DETAIL]->(merchant)
CREATE (merchant)-[r2:BANK_DETAIL]->(bank)
// Changes scope back to r
WITH r
DELETE r